
Section 2 – Statistical Machine Learning
4) Linear & Logistic Regression
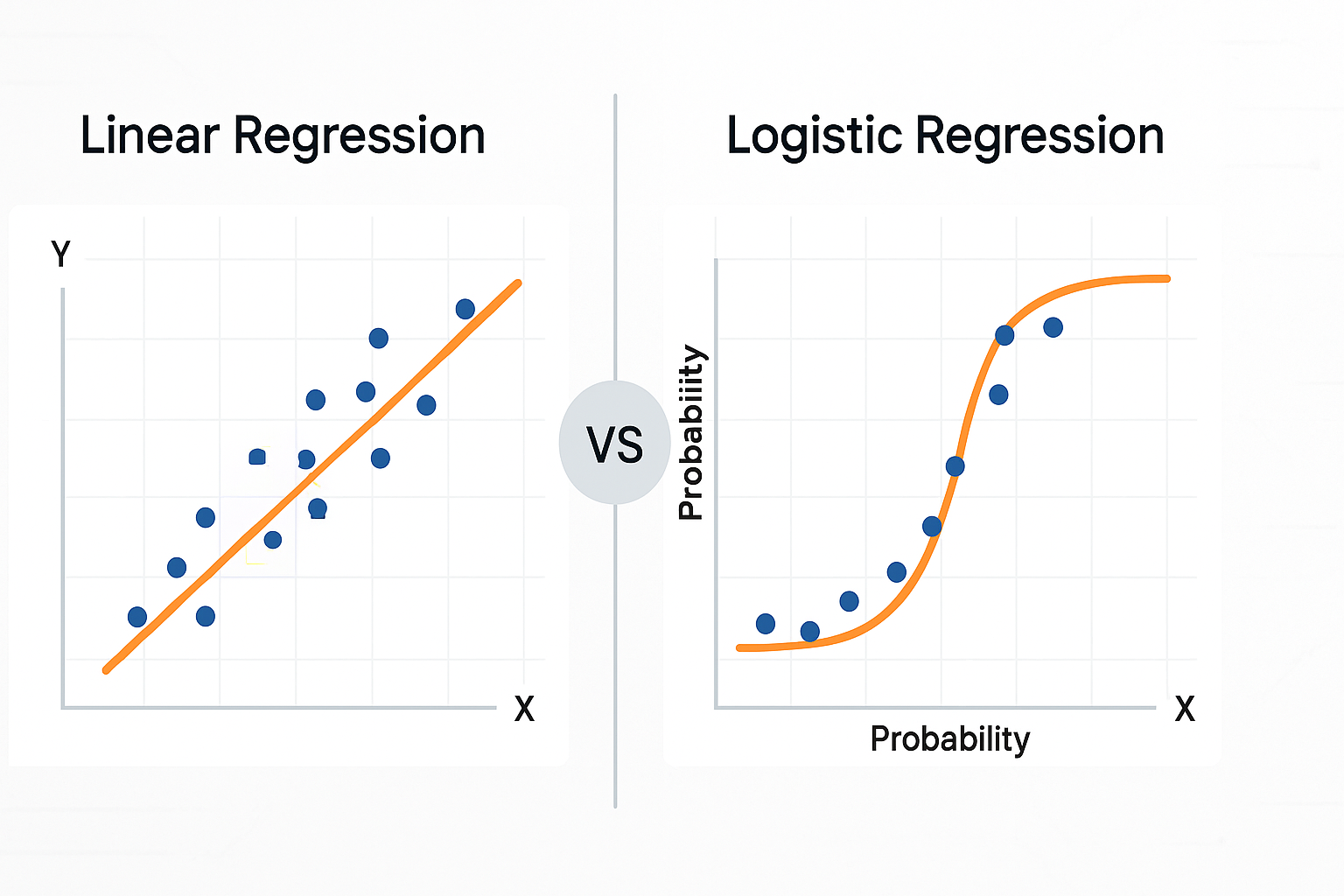
Linear Regression
“A regression model in which the conditional mean of the response variable is an affine function of the explanatory variables.”
(The Elements of Statistical Learning – Hastie, Tibshirani, Friedman)
Logistic Regression
“A generalized linear model for a binary response variable in which the log odds of the probability of the outcome are modeled as a linear function of the explanatory variables.”
(Applied Logistic Regression – Hosmer, Lemeshow)
- Linear Regression: Fits a straight line/plane to predict a number.
- Logistic Regression: Fits an S-shaped curve to predict a probability between 0 and 1.
Practical Examples
- Linear: Predict house price from area, rooms, location score.
- Logistic: Classify emails as spam or not spam.
Workflow Checklist
- Define target (numeric for linear; binary for logistic).
- Collect features; preprocess data.
- Train/test split.
- Scale features if necessary.
- Fit model with regularization.
- Evaluate (MAE, RMSE for linear; ROC-AUC, F1 for logistic).
- Inspect coefficients for interpretability.
Common Pitfalls
- Leakage of future data.
- Multicollinearity inflating coefficients.
- Outliers skewing predictions.
5) Decision Trees (Classification & Regression)
“A decision tree is a flowchart-like structure in which each internal node represents a ‘test’ on an attribute, each branch represents the outcome of the test, and each leaf node represents a class label (classification) or a numerical value (regression).”
(Classification and Regression Trees – Breiman, Friedman, Olshen, Stone, 1984)
A tree of “if-else” questions that splits data into purer groups until a final prediction is made.
Practical Examples
- Loan approval decision-making.
- Predicting machine failure based on sensor readings.
Workflow Checklist
- Preprocess data (handle missing values, encode categories).
- Limit tree depth to avoid overfitting.
- Train model; visualize tree.
- Evaluate (Confusion Matrix/F1 for classification; MAE/RMSE for regression).
- Extract human-readable rules.
Common Pitfalls
- Overfitting with deep trees.
- Instability with small data changes.
- Biased splits for high-cardinality features.
6) K-Means Clustering (Unsupervised)
“The k-means algorithm partitions n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster.”
(MacQueen, J., 1967 – Some Methods for Classification and Analysis of Multivariate Observations)
Groups similar data points into clusters, each represented by its “average” (centroid).
Practical Examples
- Customer segmentation in marketing.
- Grouping products by purchasing patterns.
Workflow Checklist
- Standardize features.
- Select
kusing Elbow or Silhouette method. - Train model; name clusters for business use.
- Validate clusters with real-world metrics.
Common Pitfalls
- Poor performance on irregular-shaped clusters.
- Sensitivity to outliers.
- Random initialization leading to different results.
Quick Reference – When to Use What
| Situation | Best Method | Why |
|---|---|---|
| Predict a number with linear trends | Linear Regression | Simple, interpretable |
| Predict yes/no with probabilities | Logistic Regression | Calibrated outputs |
| Need human-readable rules | Decision Tree | Transparent logic |
| No labels, need groups | K-Means | Quick baseline clustering |
Trivia Box
- Logistic regression is actually a classifier, not a regression model.
- Decision trees can naturally handle non-linear relationships without feature engineering.
- The “K” in K-Means is chosen by you — not learned by the algorithm.
Mini Exercises for Learners
- Linear Regression: Predict house prices from area, rooms, and location score; compare RMSE with and without regularization.
- Decision Tree: Train a tree for loan approval; limit depth to 3 and explain 3 rules.
- K-Means: Cluster customers by spend, visits, and recency; name the clusters for a marketing plan.