
Section 4 – Transformers
Transformers are neural network architectures that replace recurrence/convolutions with attention, enabling parallel training, long-range context, and scaling to very large models.
14) Why Transformers Changed AI (Key Features)
- No recurrence
Traditional RNNs process tokens step-by-step. Transformers process all tokens in parallel, using attention to let each position look at all others. - Attention mechanism
Each token computes which other tokens to focus on when producing its next representation. - Parallelisation
Because there’s no sequential dependency in the encoder (and masked parallelism in the decoder), we can fully utilise modern accelerators (GPUs/TPUs). - Scalability
Model quality improves predictably as we scale data, parameters, and compute—which is why “large language models” (LLMs) work so well.
15) Core Definitions (official-style)
- Transformer (Vaswani et al., 2017)
A sequence model built from stacked attention and position-wise feed-forward layers (plus residuals & normalization), operating without recurrence or convolution. - Self-Attention
Attention where QQQ, KKK, and VVV all come from the same sequence, letting each token attend to every other token. - Multi-Head Attention
Multiple attention “heads” (independent projections of Q,K,VQ,K,VQ,K,V) run in parallel, capturing different relation types (syntax, long-range links, etc.), then concatenated and mixed. - Positional Encoding / Position Embeddings
Since attention alone is permutation-invariant, we inject position information (e.g., sinusoidal or learned embeddings) so the model knows token order. - Encoder / Decoder
- Encoder: stacks of self-attention + FFN → contextualise inputs.
- Decoder: stacks of masked self-attention + cross-attention + FFN → generate outputs autoregressively.
Scaled Dot-Product Attention
This computes weighted combinations of values where weights reflect query-key similarity.
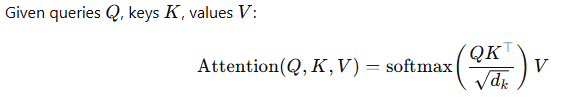
16) Architecture at a Glance
Encoder Block (×N)
- LayerNorm → Multi-Head Self-Attention → Residual
- LayerNorm → Feed-Forward (MLP) → Residual
Decoder Block (×N)
- LayerNorm → Masked Multi-Head Self-Attention → Residual
- LayerNorm → Cross-Attention (attends over encoder outputs) → Residual
- LayerNorm → Feed-Forward → Residual
Training Objectives (common)
- Masked Language Modeling (MLM): predict masked tokens (e.g., BERT).
- Causal LM: predict next token given previous tokens (e.g., GPT family).
- Seq2Seq: encode input, decode output (e.g., T5, translation).
17) Practical Benefits & Costs
Benefits
- Long-range context handling
- High throughput training (parallel)
- Strong transfer learning (pretrain → fine-tune or prompt)
Costs / Pitfalls
- Quadratic attention: memory/time scale as O(n2)O(n^2)O(n2) with sequence length
- Hallucinations in generative use—needs guardrails/RAG
- Data hunger & compute cost—quality depends on large, clean corpora
Mitigations
- Efficient attention variants (sparse, linearised, sliding-window)
- Retrieval-Augmented Generation (RAG) for up-to-date, source-grounded answers
- PEFT/LoRA to fine-tune cheaply; quantisation (8-bit/4-bit) for deployment
18) What Transformers Do Well (Applications)
- Language: translation, summarisation, Q&A, code generation, chat assistants
- Vision: classification, detection, segmentation via ViT and hybrids
- Speech: ASR (automatic speech recognition), speaker diarisation
- Multimodal: text↔image (captioning, generation), text↔audio, video understanding
- Enterprise: search & RAG over documents, analytics copilots, form understanding
- Time-series: long-context forecasting and anomaly detection (with care)
19) Popular Transformer Families (what & when to use)
- BERT (Encoder-only, MLM)
Great for understanding tasks: classification, NER, semantic search (via embeddings).
Tip: Fine-tune or use sentence-embeddings for retrieval. - T5 (Encoder-Decoder, Text-to-Text)
Unifies tasks as text in → text out (summarise, translate, QA).
Tip: Simple prompting (“summarise: …”) often works well. - GPT family (Decoder-only, Causal LM)
Strong at generation: drafting, coding, chain-of-thought, tool-use via prompting. - Whisper (Encoder-Decoder for Speech)
Robust speech-to-text across languages and accents. - ViT (Vision Transformer)
Image understanding by splitting images into patches → transformer encoder.
Tip: Fine-tune on your dataset; use augmentations. - CLIP (Vision-Language, Contrastive)
Aligns images and text in a shared space → powerful zero-shot recognition & retrieval. - DALL·E (Text→Image generation)
Produces images from prompts; modern systems combine transformer planning + diffusion decoders for fidelity and alignment.
20) Worked Examples (mental models)
- Summarisation (T5/GPT): “Summarise this report in 5 bullet points focusing on safety KPIs.”
- Retrieval-Augmented QA (GPT/BERT-embeddings): Embed docs → retrieve top-k → feed to an LLM for grounded answers.
- Image Captioning (ViT+Transformer decoder): Encode image patches → decode caption tokens.
- Speech-to-Text (Whisper): Feed audio features to encoder → decode text.
21) Hands-On: Quickstarts (low-code ideas)
- Zero-shot classify support tickets with a GPT prompt (no training).
- Fine-tune a small T5 on your FAQs for better on-brand summaries.
- Build RAG: generate embeddings (BERT/SBERT), store in a vector DB, retrieve + prompt an LLM.
- Transcribe meetings with Whisper; summarise with a T5/GPT prompt.
22) Evaluation & Safety
- Text: BLEU/ROUGE for MT/summarisation; accuracy/F1 for classification; human eval for quality.
- Vision: top-k accuracy; mAP for detection; IoU/Dice for segmentation.
- Speech: Word Error Rate (WER).
- Safety: test adversarial prompts, measure hallucination rate, add citations via RAG, log failures.
23) Visual Asset Pack (for your designer)
- “Attention Heatmap”: show a token attending strongly to earlier keywords.
- “Transformer Block”: LayerNorm → Multi-Head Attention → Add/Residual → FFN → Add/Residual.
- “Encoder–Decoder Flow”: input tokens → encoder → cross-attention in decoder → generated tokens.
- “Model Zoo” tiles: BERT, T5, GPT, ViT, CLIP, Whisper, DALL·E with 1-line use cases.
- “RNN vs Transformer” throughput comparison sketch (parallel vs sequential).
24) Mini-Exercises
- Prompting: Take a paragraph from a policy doc. Ask GPT to produce: (a) 5-bullet summary; (b) glossary; (c) action items. Compare outputs when you add role/context in the prompt.
- RAG sanity: Index 20–30 PDFs; ask factual questions. Track answer accuracy with and without retrieval.
- Vision: Try a ViT fine-tune on a small labeled set (e.g., 5–10 classes). Does freezing early layers help when data is tiny?
- ASR: Transcribe a 2-minute audio with Whisper; compute WER by manually checking errors.